





Listen to this blog
At the end of 2018, researchers at Google introduced a new groundbreaking Natural Language Processing technique called Bi-directional Encoder Representations from Transformers – or simply – BERT, which became a breakthrough development in the area of NLP. The model and its variations such as RoBERTa or DistilBERT took the Deep Learning community by storm because of its superior performance.
Challenges faced by NLP in the pre-BERT era
Before the development of BERT, the NLP industry faced several significant challenges which were mostly around the training of NLP models. This was a tedious task; one that would rarely do a great job on domain-specific projects. Leo Dirac, a founder of a stealth startup and an ex-senior principal engineer at Amazon, outlined those challenges as follows:
- NLP models – specifically LSTM – were very difficult to train as they are comprised of very deep neural networks that lead to very long gradient paths.
- LSTM models were also very bad at transfer learning. Transfer learning hardly worked with LSTM but was possible with CNN and computer vision problems.
- Every time LSTM was used, it needed a specifically labeled dataset for every task, which was time-consuming and expensive. Since the NLP arena is domain-specific and contains many distinct topics and tasks (e.g., pharmacy vs. banking industry), most domain- or task-specific datasets contain only several hundred human-labeled training examples.
The impact of BERT on NLP
When BERT came into the picture, the world of NLP changed. Whether it was sentiment detection, classification, machine translation, named entity recognition, summarization, and question answering – you name it and BERT could do it all.
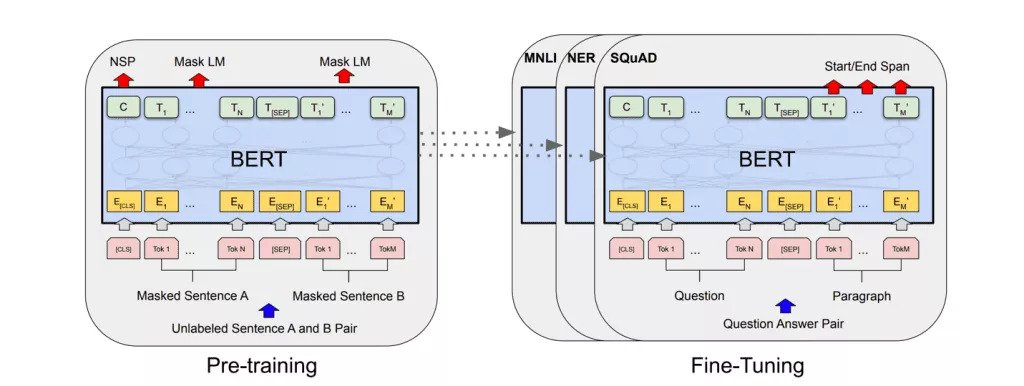
Here’s how BERT solved most of the aforementioned problems:
Bi-directionally trained
In the pre-BERT world of model training, an NLP model would have to read a text sequence from either left-to-right or combined left-to-right and right-to-left, but not at the same time. BERT, that is bi-directionally trained, has a deeper sense of language context compared to the single-direction language models.
Enhanced word prediction capabilities
By combining Mask Language Model (MLM) with Next Sentence Prediction (NSP), BERT randomly masks a word in a sentence and then tries to predict it. Because BERT can predict missing words in the text, and because it analyzes every sentence with no specific direction, it does a much better job at understanding the meaning of homonyms than the previous NLP techniques.
Fine-tuned on smaller datasets
Pre-trained BERT solves the problem of data scarcity. The main goal of the pre-trained BERT models is to be fine-tuned on smaller task-specific datasets, e.g., when working with problems like question answering, sentiment analysis, or specific domains.
Is BERT still the best AI model for NLP?
Let’s go over the recent progress in the NLP area, and review some of the alternative models in this space.
XLNet: Better fine-tuning strategy
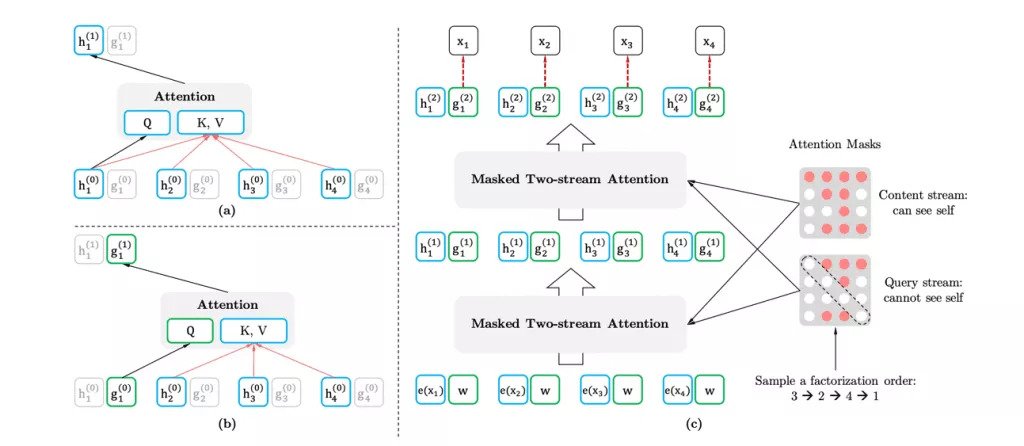
Nothing is perfect, and BERT has demonstrated that it has its shortcomings. For example, masking that is used during pre-training BERT is ignored from real data during finetuning time, and this leads to a pre-train-fine-tune discrepancy. Let’s say we have the following sentence “The housing crisis of 2008 was responsible for the main financial crisis on Wall Street”. The model masks ‘housing’ and ‘crisis’, and even though we know the masked ‘housing’ and ‘crisis’ contain implicit relation to each other, it predicts ‘housing’ given the unmasked tokens, and predicts ‘crisis’ given the unmasked tokens separately. It ignores the relation between ‘housing’ and ‘crises.’ In a nutshell, BERT assumes the predicted words are independent of each other. XLNet, on the other hand, uses all possible permutations of the factorization to maximize the expected log likelihood. This allows the context for each position to incorporate tokens from both left and right and capture bi-directional context from all positions. Thus, compared to BERT, XLNet is independent of surrounding words, and, hence, does not suffer from the pre-train-fine-tune discrepancy, unlike the assumption of independence made in BERT.
pQRNN: Better training time
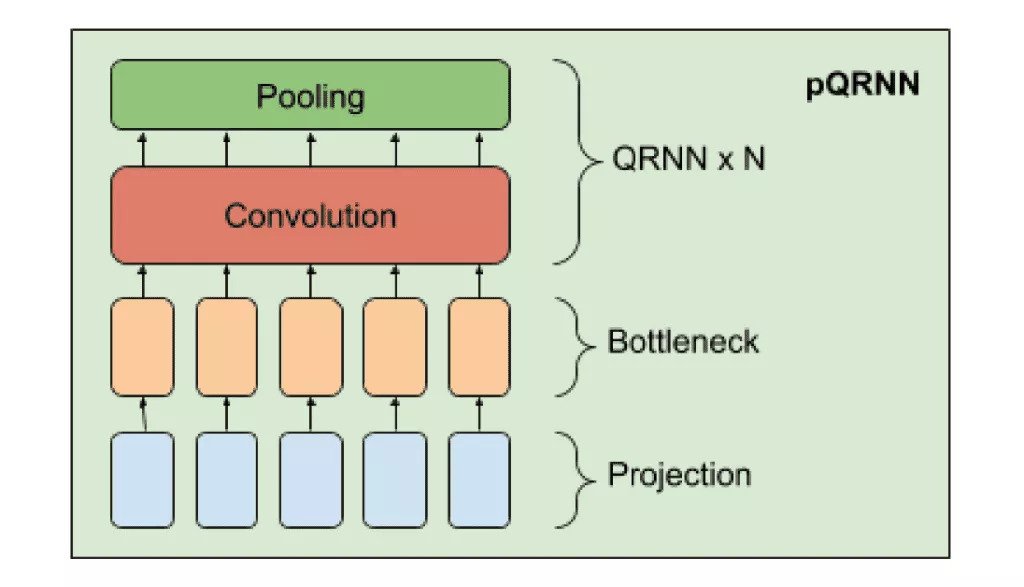
BERT is also slower than its predecessors, and it takes some time to train. BERT-Base has 110 million parameters and the BERT-Large model has 330 million parameters. Depending on the GPU, it can take several days to train a BERT model. Let’s say, a new startup needs to build something fast and at no significant cost. In specific scenarios where there is no budget to buy GPUs and something needs to be built relatively fast, Projection Quasi-RNN, or pQRNN, can deliver a performance that is comparable to BERT in a relatively short time without the required pre-training period for BERT.
pQRNN (an extension of the projection attention neural network PRADO) significantly outperforms the LSTM model without the required pre-training being 140x smaller. pQRNN can achieve over 95.9% performance of an mBERT teacher on some datasets being 350x smaller. Consequentially, pQRNN can achieve BERT-level performance despite being trained with single monitored data. Just like PRADO, pQRNN embodies a projection layer that helps the model to learn the most relevant tokens, however, there is no predetermined set of parameters to specify these tokens. After recognizing a token, it uses a mapping function to convert it into a treble feature vector. Thus, a text represents a treble vector sequence that constitutes a bottleneck layer that is then sent to be processed by pooling and convolution layers that are represented by several bi-directional QRNN encoders.
SMITH: Better handling of long texts
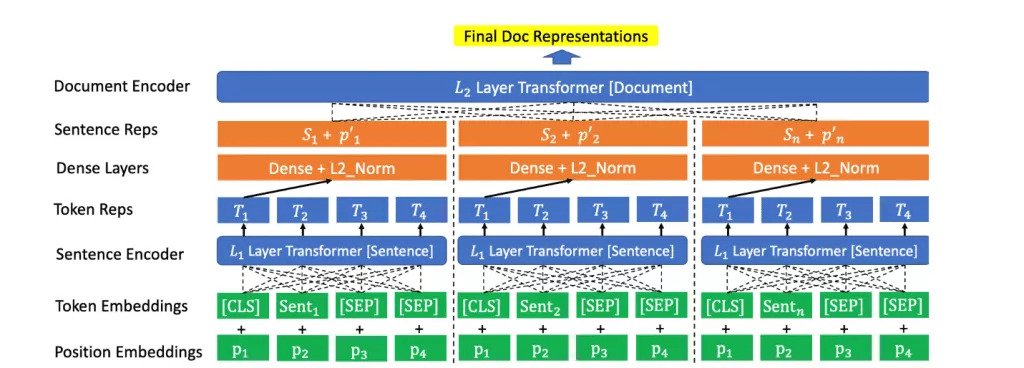
Another problem with BERT is that it cannot handle long text sequences. By default, BERT supports only up to 512 tokens. But what if one needs to process large documents? In the BERT world, to overcome this problem, researchers either ignore text after 512 tokens that can lead to a loss of information or split tokens into 2 or more inputs to predict it separately. That is, the BERT algorithm is strictly limited to understanding only short documents. On the other hand, SMITH (Multi-depth Transformer-based Hierarchical Encoder), can grasp larger blocks of sentences within the context of an entire document. Just like BERT, SMITH also adopts the “unsupervised pretraining + fine-tuning” paradigm for the model training.
In addition to the original masked word language modeling task used in BERT, SMITH uses a masked sentence block language modeling task for long text inputs. Therefore, the model masks both randomly selected words and sentence blocks during its pre-training. The final loss consists of the masked sentence block prediction loss and the masked word prediction loss. The SMITH fine-tuning process is similar to BERT, where the word-sentence level masks are removed, and model parameters are initialized with pre-trained checkpoints with the text matching loss only. This mechanism increases the maximum input text length from 512 to 2048 when compared with BERT-based baselines. This fact of SMITH being able to process long text sequences, something that BERT is unable to do, is what makes the SMITH model novel and fascinating.
MT-DNN: Better domain generalization
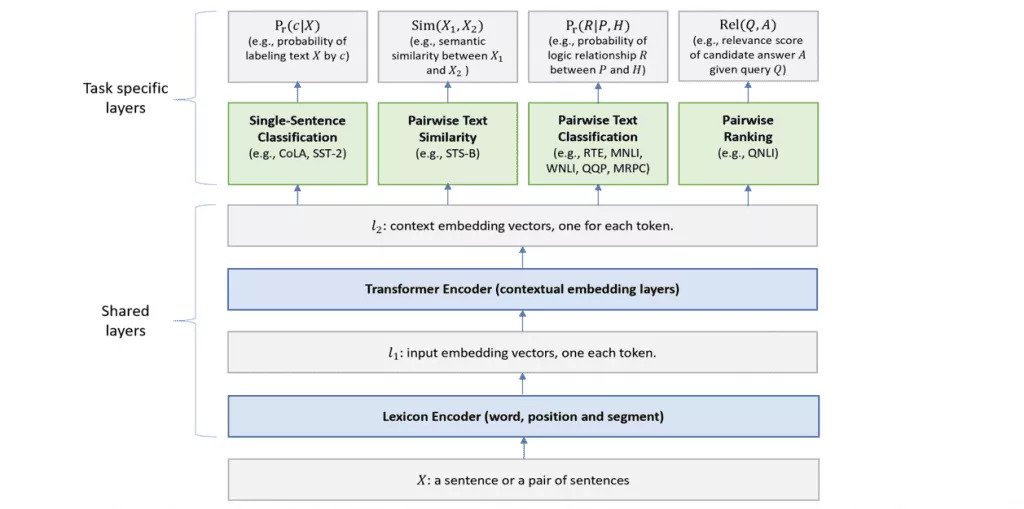
While the previously described models corrected for shortcomings of BERT and demonstrated comparable performance to BERT, MT-DNN (Multi-Task Deep Neural Network), an NLP model proposed by Microsoft researchers, significantly outperforms BERT in nine of eleven benchmark NLP tasks. It extends DNN (deep neural networks) while incorporating a pre-trained bi-directional transformer language model BERT, thus, allowing for domain adaptation with substantially fewer in-domain labels than the pre-trained BERT representations.
The training procedure of MT-DNN involves two stages: pretraining and multi-task learning. The pretraining stage is identical to the BERT model. Two unsupervised prediction tasks namely masked language modeling and next sentence prediction are used to learn the parameters of the lexicon encoder and transformer encoder. In conclusion, compared to BERT, MT-DNN showcases superior performance as it supports large amounts of cross-task data and draws advantage from a fine-tuning effect that helps it adapt much better to new tasks and domains.
Parting thoughts
It’s been over 2.5 years since the ground-breaking BERT entered the NLP industry. The industry is progressing in days, if not hours, and the future of massive and novel deep learning models is quite promising. While scientific research in the realm of NLP is advancing by leaps and bounds, we predict a significant increase in progress in this space in the upcoming years. Tech companies (and especially consulting companies) need to keep up with this progress to meet the diversity of the challenges in the industry while staying in touch with the latest NLP techniques.