




Listen to this blog
In order to set an optimal premium amount, insurance companies use actuarial methods to predict the size of actual claims that are expected to be submitted by their customers. The assumption behind these actuarial models is that the expected loss depends on various attributes of the policyholder. In auto insurance, for example, these attributes are the policyholder’s car record points, age, car model, and city population.
Actuarial techniques from the 80s and 90s use linear models to encode the claim sizes of each policyholder profile into model parameters. These models mostly assume that the submitted claims follow a normal distribution. However, if we look at a typical insurance claim database, insurance claim amounts are not normally distributed. Almost half of all policyholders do not submit any claims, which means zero is the most frequent claim size. The remaining customers submit claim amounts that follow a right-skewed distribution. Such a distribution is shown in the following histogram:
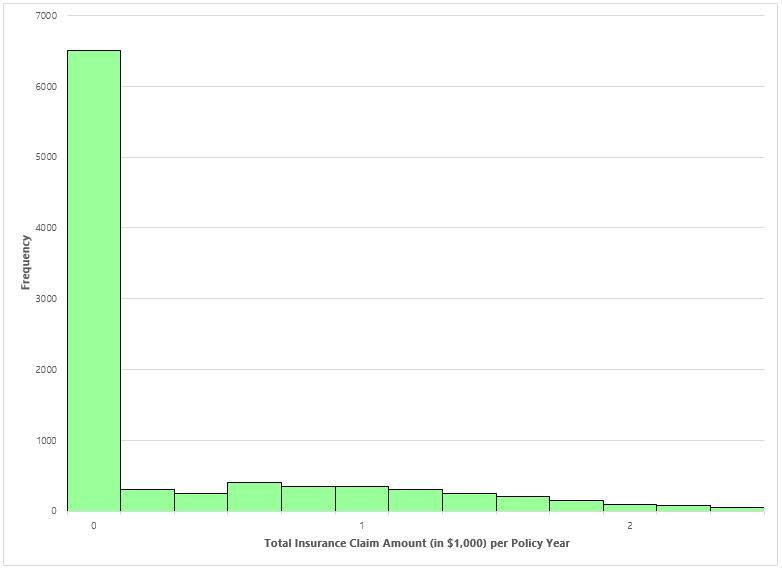
Actuarial science’s linear models typically encode all customer profiles into a single model; and looking at the above distribution, a car insurance database may look something like the following:
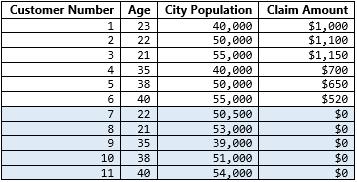
![]()
Note: The table and histogram above present a simplified example for nontechnical readers, and aren’t meant to hold up to mathematical scrutiny.]
History has provided the above data distribution, when encoded into a single linear model, will not always result in an accurate predictor.
The figure below shows a sample fitting of a single linear model compared to an alternate scheme of multiple models fitted for partial datasets.
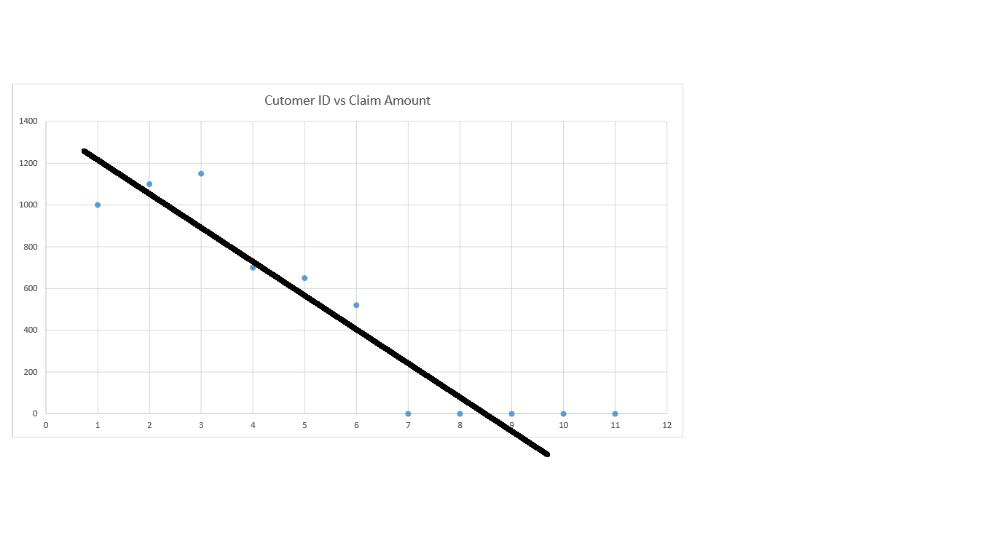
![]()
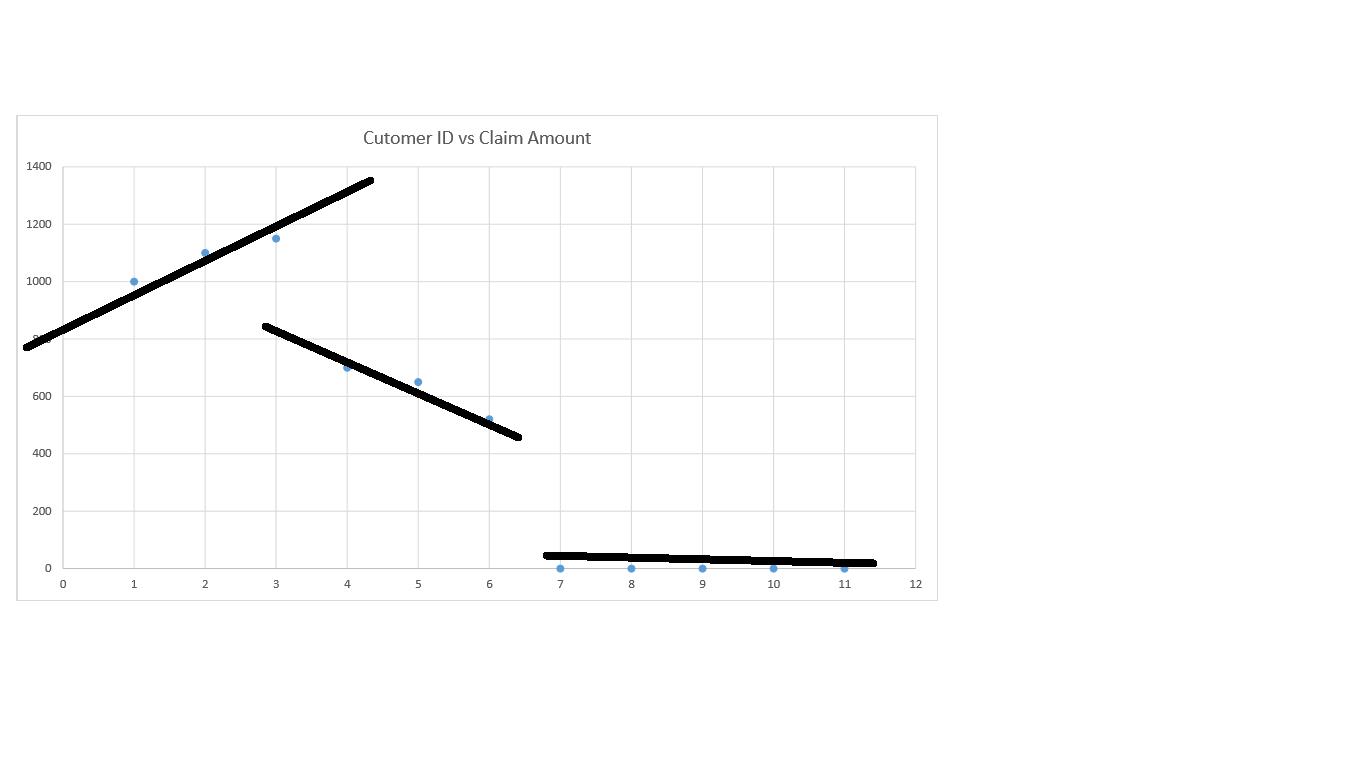
![]()
Of course, multiple smaller models trained for subsets of the data is Visionet’s message here. This approach uses a machine learning technique called the “gradient tree-boosting algorithm”. This algorithm is used in our software offering to model individual policyholders’ claim sizes, where it picks some policies and trains a model on those. It uses the rest of the policies’ data to test prediction accuracy. Those test profiles that result in bad predictions using the first model are declared as candidates for training a new model. This process goes on until all policy data is correctly converted in to multiple models. These models are then combined into one bigger model where each future customer profile is passed as input and the model returns a claim size prediction.
Our “Insurance Claim Size Predictor” can be deployed on-premises in a private cloud or used via our SaaS offering. We provide data science support for training models on insurers’ specific data features and customize our models accordingly. Visionet’s data science team of PhDs can be aligned with client’s actuarial scientists to infuse advanced deep machine learning into traditional insurance risk models.